by Alper9000
|
|
by Alper9000
|
|
Questo documento vuole essere una semplice introduzione ai meccanismi della compressione audio.
Tratta dei concetti basilari delle onde sonore, delle differenze tra analogico e digitale, di come l’audio è creato ed immagazzinato digitalmente, del perché sia utile e come sia possibile comprimere i file audio e dei principi su cui si basano le compressioni audio "lossless" e "lossy".
Udito umano e onde sonore
L'uomo, nei suoi rapporti con l'ambiente, avverte continuamente dei suoni e dei rumori; anzi, di questa facoltà egli soprattutto si serve per una più perfezionata comunicazione con i suoi simili.
Questo fenomeno, apparentemente reso banale dall'abitudine, ha imposto in realtà alla natura la soluzione di numerosi e complessi problemi tecnici.
Vediamo innanzitutto che cosa è il suono dal punto di vista fisico.
Se, per esempio, facciamo urtare tra loro due pezzi di ferro, si produrranno in essi delle vibrazioni e nelle zone d'aria più vicine si verificherà, ad ogni vibrazione, un addensamento di molecole, seguito immediatamente da una rarefazione. Ogni addensamento e rarefazione si trasmettono poi alla zona immediatamente circostante, e così via di seguito.
In altre parole, si realizza la formazione di un'onda che si propaga tutt'intorno e che, quando giunge al nostro orecchio, viene percepita come suono.
Quindi, il suono è un'onda, più o meno complessa, più o meno regolare, dovuta alle vibrazioni delle molecole di un "mezzo" (che, nel nostro caso, è rappresentato dai gas dell'aria). Da ciò deriva che laddove ci sia il vuoto assoluto non potrà essere udito alcun suono o rumore.
La musica, dunque, è fatta di onde.
Quando un chitarrista pizzica una corda, questa vibra ad una certa frequenza e crea un'onda sonora. Questa, viaggiando attraverso l'aria, arriva all’orecchio, o meglio arriva a quella parte chiamata orecchio esterno (costituita dal padiglione auricolare e dal condotto uditivo esterno), dove fa vibrare la sottile membrana del timpano. La vibrazione del timpano si trasmette a sua volta alla catena dei tre ossicini dell’orecchio medio (martello, incudine e staffa): i loro movimenti sono amplificati venti volte e si trasmettono all’orecchio interno.
Qui, in una piccola struttura detta coclea (o chiocciola), hanno sede migliaia di cellule cigliate (circa ventimila per ciascun orecchio) capaci di dividersi i compiti: alcune lavorano con i suoni forti, altre con i deboli. Le cellule cigliate sono responsabili di una nuova traduzione dei suoni, da vibrazioni a impulsi elettrici, che tramite le sottili fibre del nervo cocleare arrivano all’area uditiva del cervello, dove finalmente si ha la vera percezione dei suoni.
Insomma, tutto quello che noi sentiamo lo possiamo sentire perché qualcosa sta vibrando e sta creando onde sonore.
In una tromba, è una colonna di aria. In una chitarra elettrica, le corde vibranti inviano un segnale attraverso l'amplificatore, il quale causa la vibrazione del cono dell’altoparlante nello stesso modo della sequenza originale. Quando noi parliamo o cantiamo sono le nostre corde vocali a vibrare.
I suoni
Abbiamo ormai capito che i suoni sono fenomeni fisici di carattere ondulatorio che stimolano il senso dell'udito. Le vibrazioni sonore percepibili dall'uomo si collocano a frequenze comprese tra i 15 e i 20.000 hertz (approfondiremo poi l'argomento delle frequenze).
Il significato del termine "suono" è però stato esteso dai fisici moderni anche a fenomeni ondulatori che si verificano in campi di frequenza situati al di fuori del campo di udibilità dell'orecchio umano ed in particolare ai suoni di frequenza superiore ai 20.000 hertz, che sono detti ultrasuoni.
Il suono è costituito da onde meccaniche longitudinali: le molecole del mezzo in cui si propagano si muovono parallelamente alla direzione di propagazione dell'onda. Un'onda sonora che viaggi attraverso l'aria non è altro che una successione di rarefazioni e compressioni di piccole porzioni d'aria; ogni singola molecola trasferisce energia alle molecole adiacenti e, dopo il passaggio dell'onda, ritorna pressappoco nella sua posizione iniziale.
Qualunque suono semplice, come quello di una nota musicale, è descritto da tre diverse caratteristiche percettive: l’altezza, l’intensità e il timbro.
Queste caratteristiche corrispondono rispettivamente a tre grandezze fisiche: frequenza, ampiezza e spettro.
Frequenza >>>>>>>> Altezza
Ampiezza >>>>>>>>> Intensità
Spettro >>>>>>>>>>> Timbro
|
|
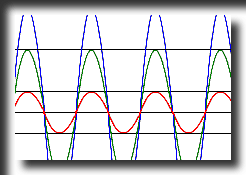
Onde sonore di uguale frequenza e diversa intensità |
|
|
Onde sonore di uguale intensità e diversa frequenza |
Il rumore, invece, è un suono complesso, dato dalla sovrapposizione casuale di frequenze diverse, non armonicamente correlate, che quindi non può essere descritto da questi tre parametri.
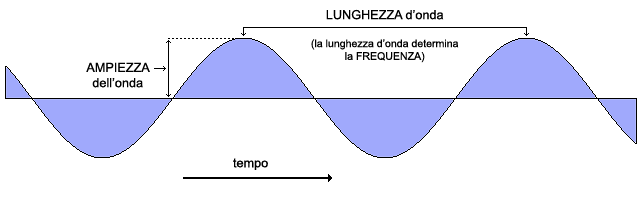
La lunghezza d’onda è la distanza tra due punti corrispondenti dell’onda sonora: nell’esempio in figura è la distanza tra due picchi (creste) successivi dell’onda, ma può anche essere tra due punti più bassi (ventri) successivi, ecc. In altre parole, la lunghezza d'onda può essere definita come la distanza percorsa da un'onda nell'intervallo di tempo di un periodo, o equivalentemente, distanza tra due punti consecutivi e di uguale fase di un'onda, oppure ancora come la distanza tra due creste o due ventri successivi.
Dalla lunghezza d'onda si determina la frequenza.
La frequenza di un'onda si riferisce a quante volte al secondo l’onda passa dal suo punto più alto al suo punto più basso e di nuovo al punto più alto. In altre parole, la frequenza è il numero di oscillazioni complete che l’onda compie nell’unità di tempo (di solito, in un secondo). Per oscillazione completa si intende il passaggio dell’onda dal suo punto zero al picco massimo, poi di nuovo al punto zero, al punto minimo e ancora al punto zero.
La frequenza è quindi il numero di queste oscillazioni, misurato tipicamente in Hertz (Hz), dal nome del fisico tedesco H.R. Hertz (1857 - 1894), o cicli per secondo.
Per quantificare i fenomeni ad alta frequenza si impiegano generalmente i multipli dell'hertz: il kilohertz (kHz), pari a mille cicli al secondo, il megahertz (MHz), pari a un milione di cicli al secondo, e il gigahertz (GHz), pari a un miliardo di cicli al secondo.
La frequenza di un'onda determina l'altezza di un suono (in inglese, pitch), cioè la tonalità audio del suono. Maggiore è la frequenza, più alto è il suono percepito. Più precisamente, i suoni gravi hanno una frequenza dell’ordine delle decine di hz, mentre i suoni più acuti hanno una frequenza dell’ordine delle migliaia di hz.
Come abbiamo già ricordato, in media l’orecchio umano riesce a percepire frequenze comprese tra 15 Hz e 20.000 Hz (20 kHz).
L'altezza, in musica, è quindi l'elevazione di un suono, determinata dalla rapidità delle vibrazioni che lo producono.
I livelli standard dell'esatta intonazione hanno subito variazioni nel corso dei secoli.
Nel Rinascimento, gli strumenti a fiato erano costruiti abitualmente in modo tale che la nota LA avesse un'altezza di circa 466 vibrazioni al secondo, ed era quindi più alta del LA attuale di circa un semitono.
Alla fine del Seicento i fabbricanti di strumenti la abbassarono a circa 415 hertz, ossia quasi un semitono sotto l'altezza odierna.
Tra il XVIII e il XIX secolo gli strumenti a fiato furono costruiti con intonazioni sempre più alte, raggiungendo alla metà dell'Ottocento un LA di circa 452 hertz.
Si cercò ripetutamente di fissare uno standard di altezza; il tentativo più autorevole fu quello di una commissione francese di musicisti e scienziati che si riunì nel 1858-59. Il gruppo di studiosi si espresse a favore del LA = 435 Hz, l'altezza più usata in Francia.
Nel 1887 questa misura venne ufficialmente adottata dal congresso che si tenne a Vienna, una conferenza internazionale sulle altezze, e ha oggi il nome di altezza internazionale, o diapason normal.
L'altezza francese, però, non fu accettata universalmente. La Gran Bretagna e gli Stati Uniti, infatti, adottarono il LA = 440 Hz, misura ancora oggi in uso in questi paesi, nonostante si faccia da molte parti pressione perché sia portata ancora più in alto.
La frequenza delle onde sonore è la grandezza fisica su cui si basa l’organizzazione dei suoni in scale musicali e la teoria dell’armonia.
L'intervallo che separa due note con frequenze l’una il doppio dell'altra viene chiamato "ottava".
L’intervallo di un’ottava è suddiviso a sua volta in sette intervalli di frequenze, corrispondenti alle sette note musicali.
Ogni coppia di note consecutive è caratterizzata da un rapporto di frequenze ben definito; ad esempio, il rapporto tra la frequenza del RE e quella del DO è uguale a quello tra il SOL e il FA e corrisponde a un tono; il rapporto tra il FA e il MI, invece, come quello tra il DO e il SI, corrisponde a un semitono.
Più in generale, ad ogni intervallo compreso fra due note qualsiasi corrisponde un rapporto di frequenze dato: ad esempio, una quinta rappresenta l'intervallo fra due note che hanno un rapporto di frequenze di 3/2; una terza maggiore corrisponde al rapporto di frequenze 5/4.
Una legge fondamentale dell’armonia afferma che due note emesse contemporaneamente producono un suono eufonico, ovvero armonioso all'orecchio, se le loro frequenze distano di un'armonica; per estensione, un accordo di più note è eufonico se le frequenze delle note stanno in rapporti di piccoli numeri interi. In caso contrario si produce una dissonanza.
L'ampiezza di un'onda sonora rappresenta il massimo spostamento, rispetto alla posizione di equilibrio, che le molecole del mezzo di propagazione compiono al passaggio dell’onda. Essa è dunque il valore massimo che l'onda raggiunge nel tempo e si riferisce a metà della distanza tra il punto più alto di un'onda e il suo punto più basso.
Al crescere dell'ampiezza, aumenta la forza con la quale viene colpito il timpano dell'orecchio e quindi l'intensità con cui il suono è percepito.
Dall’ampiezza dipende quindi l’intensità (volume) del suono, vale a dire il rapporto tra la potenza trasportata dall’onda e la superficie su cui essa incide. Più è grande l'ampiezza di un'onda e più risulta alto il suo volume.
L’unità di misura di questa grandezza nel Sistema Internazionale è il watt/m2.
Più comunemente, però, in acustica si suole esprimere l’intensità dei suoni tramite una grandezza fisica ad essa collegata: il decibel (dB), unità di misura su base logaritmica.
L’impiego dei logaritmi è particolarmente adatto quando si deve quantificare l’intensità dei suoni percepibili dall’orecchio umano, dato che questo percepisce i rumori proprio secondo una scala logaritmica.
Il dB è definito come il logaritmo in base 10 del rapporto tra l’intensità effettiva del suono e un’intensità fissa di riferimento (normalmente si usa la più bassa intensità udibile). Il decibel corrisponde, quindi, al logaritmo della pressione sonora avvertita dal timpano in rapporto a un valore di riferimento di 0 dB e corrispondente, in pratica, a un suono con frequenza pari alla soglia di percezione dell'orecchio umano.
Un raddoppio dell’intensità percepita corrisponde a un aumento di 10 volte dell’intensità effettiva del suono.
In altre parole, ogni aumento di 10 dB corrisponde ad un raddoppio del volume.
Per avere qualche termine di paragone, in un ambiente tranquillo un misuratore può indicare in media un'intensità di circa 33 - 38 dB; una conversazione a volume medio porta la misura a 60 - 70 dB; in un concerto rock si raggiungono facilmente i 120 - 125 decibel, mentre l'intensità sonora emessa da un jet al decollo può raggiungere i 150 dB.
Il range di decibel udibili dall’orecchio umano è variabile e dipende dalla frequenza del suono in questione, ma grosso modo va da 0 a 120.
A valori di oltre 120 dB il suono determina fastidio.
A valori di oltre 138 dB il suono determina dolore.
Entro certi livelli di frequenza, la percezione dei suoni come
rumori molesti dipende spesso da valutazioni soggettive (il rombo di una
motocicletta, ad esempio, è solitamente giudicato poco fastidioso dal
conducente). Esistono, comunque, suoni che una larga maggioranza di persone
avverte come sgradevoli e quindi vengono associati a fastidio, disturbo o
disagio.
La prolungata esposizione a rumori "molesti" può provocare
astenia, cefalee, disturbi al sistema nervoso, stress, disturbi gastrici,
depressione, alterazioni del ritmo cardiaco e della pressione arteriosa.
Una stessa nota, ad esempio il LA nella scala diatonica del DO maggiore, suonata con la stessa intensità da un pianoforte, un violino e un diapason, produce una sensazione uditiva diversa perché, pur avendo frequenza identica, ha nei tre casi un timbro diverso.
Il timbro è il "colore" caratteristico di un suono. La qualità timbrica di un dato suono vocale o strumentale è determinata dal modo in cui quel suono è prodotto (per percussione, soffiando ecc.) e dal modello caratteristico degli armonici, relativamente forti e deboli, che ciascun suono genera. Questi due aspetti si percepiscono soprattutto nell'attacco (l'inizio) della nota, che è la parte più distintiva di ogni suono. La parte sostenuta di una nota è meno facile da distinguere e può capitare, ascoltando una nota tenuta a lungo, di scambiare perfino uno strumento a corde con uno a fiato e viceversa.
Secondo il Teorema di Fourier qualsiasi onda può essere considerata come la somma di un insieme di onde, di cui la prima è detta fondamentale e le onde successive prendono il nome di armoniche.
Infatti, fino a questo punto ho parlato praticamente solo dei toni puri, cioè dei suoni semplici, monofrequenziali, che però sono quasi sconosciuti in natura, dove, invece sono presenti i suoni complessi (costituiti dalla presenza contemporanea di più suoni semplici). Nel linguaggio parlato, nella musica e nel rumore è raro percepire toni puri poiché una nota musicale contiene, oltre alla frequenza fondamentale, anche le armoniche successive.
Il parlato comprende un gran numero di
suoni complessi, alcuni dei quali (ma non tutti) in relazione armonica tra loro.
Il rumore è costituito da una mescolanza di frequenze anche molto diverse
(paragonabile alla luce bianca, che è la combinazione di tutti i colori) e
rumori diversi si distinguono per il diverso peso delle varie frequenze
componenti per cui la loro descrizione può avvenire solo valutandone lo
spettro e cioè il peso in dB di ciascuna frequenza componente.
Le armoniche sono frequenze multiple della frequenza fondamentale e di minore ampiezza (intensità). Ad esempio, se il LA fondamentale vibra a 440 kHz, la seconda armonica avrà frequenza di 880 kHz, la terza 1760 kHz, e così via.
Il numero delle armoniche ed i loro rapporti di intensità determinano il timbro, cioè la ricchezza del suono. Come abbiamo già detto (e come ovviamente tutti sappiamo), si possono distinguere le stesse note emesse da sorgenti differenti. E' la presenza delle armoniche, con le loro rispettive intensità, che ci permette di distinguere un DO emesso da un violino da quello emesso da... una sirena.
Mentre il LA emesso dal diapason ha una frequenza pari esattamente a 440 Hz, quello prodotto dal violino o dal pianoforte ha come componente di frequenza dominante sempre quella fondamentale (di 440 Hz), ma contiene anche armoniche, cioè suoni di frequenze multiple: 880, 1320, 1760 Hz ecc..
Come si è più volte detto, l'orecchio umano è sensibile a suoni di frequenza compresa tra i 15 Hz e 20.000 Hz. Tuttavia, la sensibilità varia a seconda del particolare intervallo di frequenze: quello in cui è più alta è compreso tra i 2000 e i 5000 Hz.
La capacità di risoluzione dei suoni, ovvero di distinguere due note pure poco diverse in frequenza o in altezza, dipende dall’intervallo di frequenze e dall’intensità. Per suoni di moderata intensità, nella gamma di frequenze in cui l'orecchio è più sensibile, si può percepire una differenza di ampiezza del 20% (1 dB), e una differenza di frequenza di circa lo 0,3% (circa un ventesimo di una nota). In questa stessa gamma, la differenza tra il suono più debole percepibile e quello più forte che possa essere avvertito senza provocare sensazione di dolore è pari a circa 120 dB (corrispondente a una differenza d'ampiezza di mille miliardi di volte).
Note di frequenza identica ma di intensità molto diversa possono sembrare di altezza leggermente differente; inoltre, mentre ad alte intensità l'orecchio ha la stessa sensibilità alla maggior parte delle frequenze, a basse intensità è molto più sensibile alle frequenze medie.
Di conseguenza, uno strumento di riproduzione dei suoni perfettamente funzionante può sembrare difettoso nella riproduzione a basso volume sia delle note più acute sia di quelle più gravi.
Analogico e digitale
La comunicazione analogica si basa sulla somiglianza (analogia) tra la grandezza comunicata e il dato da comunicare, mentre la comunicazione digitale trasmette l’informazione dopo averla codificata in una stringa di cifre di un sistema numerico opportunamente scelto.
La comunicazione analogica è utilizzata da tutti gli strumenti che trasmettono una grandezza il cui valore varia con continuità e che rispecchia un’analoga variazione continua della grandezza che si vuole rappresentare.
Ad esempio, è analogica la comunicazione del tachimetro di un’autovettura, di un termometro a mercurio o di un orologio a lancette, che mostrano dati variabili con continuità, seguendo, rispettivamente, le variazioni continue di velocità, temperatura e tempo.
I segnali analogici, dunque, consistono in una tensione elettrica che segue nel tempo l'andamento del segnale originale. Nei segnali audio la tensione elettrica è molto simile all'andamento dell'onda sonora originale (molto simile, non identica, perché vi è sempre l'introduzione di una quota di distorsione e di rumore, non presenti nel segnale originale).
Nel caso dei segnali digitali invece, il segnale viene rappresentato da una serie di numeri, ciascuno dei quali rappresenta il valore della pressione istantanea in un dato istante.
I dispositivi basati sul sistema di comunicazione digitale rappresentano, per mezzo di un codice in cifre, i valori delle grandezze da trasmettere, anche se queste variano con continuità. Utilizzano quindi la campionatura di tali grandezze a successivi intervalli di tempo, molto ravvicinati, e la codifica dei valori campionati in un sistema numerico prefissato.
Ad esempio, sono dispositivi basati sulla comunicazione digitale il contachilometri di un’autovettura o l’orologio munito di display a cristalli liquidi, che convertono in cifre, rispettivamente, una distanza o lo scorrere del tempo. Questi dispositivi aggiornano l’informazione mostrata a tempi discreti, effettuando comunque un’approssimazione rispetto alla reale variazione della grandezza in questione.
Benché la natura umana sia meglio disposta a relazionarsi con il formato analogico dei segnali, motivi di economicità e rapidità della comunicazione, accompagnati da un rapido e intenso progresso tecnologico nel campo dell’elettronica, hanno portato nell’ultimo decennio la forma digitale di comunicazione a prendere il sopravvento su quella analogica.
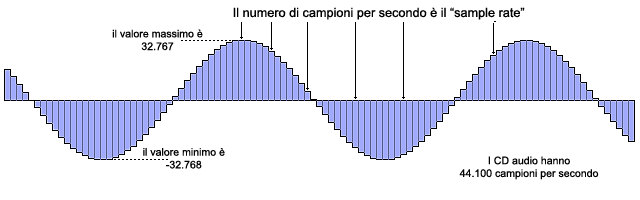
Già all’epoca della II Guerra mondiale erano in corso sperimentazioni sull’audio digitale, con conversioni di onde sonore analogiche in valori discreti. Questi studi furono portati a termine "campionando" l'onda sonora molte volte al secondo. Ogni campione registrava l'ampiezza dell'onda in quel punto (incluso se l'onda era "su" o "giù").
Il processo di conversione da analogico a digitale inizia con l’ingresso di segnali audio analogici. L’intensità del segnale è misurata a intervalli di tempo discreti, ma abbastanza ravvicinati da permettere la ricostruzione fedele del segnale: il numero di volte in cui un segnale audio in ingresso è misurato in un determinato periodo di tempo è definito frequenza di campionamento (in inglese, sample rate o sample frequency).
Questi intervalli devono essere sufficientemente brevi da distinguere le frequenze del suono udibili. Un importante aspetto è che si tratta di numeri interi, cioè che non hanno una parte decimale. Questi numeri costituiscono quindi un insieme discreto: non è possibile rappresentare tutti i valori, ma solo quelli che corrispondono a un intero. Invece i segnali analogici non sono discreti, ma continui. Allora al momento di misurare l'ampiezza di ogni gradino questa dovrà essere approssimata ad un intero, commettendo così un errore più o meno grande.
In base al teorema di Shannon-Nyquist, la frequenza di campionamento deve essere almeno il doppio della frequenza più elevata del segnale audio da digitalizzare. Una frequenza di campionamento inferiore potrebbe produrre artefatti o dissonanze nell'incisione, cioè modelli d’interferenza noti come aliasing.
Negli anni ‘70, quando Philips e Sony iniziarono a cercare un modo di migliorare la qualità audio della musica registrata, si rivolsero al campionamento digitale. Fu scelto un sample rate di 44.100 campioni per secondo (44.1 kHz) sia perché era superiore all’obiettivo fissato e cioè superiore ai 40 kHz (che rappresenta il doppio della massima frequenza, 20 kHz, percepibile dall’orecchio umano), sia perché rappresentava il massimo di informazioni che potevano essere immagazzinate su nastro (che è stato il mezzo di archivio di scelta fino a che non furono perfezionati quei piccoli dischi argentati che oggi conosciamo come CD. Per la cronaca, il primo CD è apparso nel 1981, riscuotendo un immediato e largo successo).
Il numero di bit utilizzati per descrivere ogni campione determina la gamma dinamica del suono, ossia la differenza tra il livello sonoro di massima intensità e il più debole (in altre parole, la gamma dinamica rappresenta l’estensione dal minimo al massimo valore rappresentabile).
Ad ogni bit corrisponde una gamma dinamica di 6 dB.
Quindi possiamo rappresentare alcuni valori in una tabella:
|
GAMMA DINAMICA
|
||||||
| bit | 8 | 12 | 16 | 18 | 20 | 24 |
| dB | 48 | 72 | 96 | 108 | 120 | 144 |
Per creare una registrazione digitale di musica ad alta fedeltà, nel formato Cd-Audio è stato deciso che ogni campione fosse archiviato come dato binario a 16 bit (gamma dinamica 96 dB), ossia 65.536 diversi valori o 32.768 gradini intermedi discreti tra i suoni più intensi e quelli più deboli.
Per valori maggiori di bit la qualità è migliore perché la discretizzazione è sicuramente più precisa (infatti 20 bit corrispondono a 1.048.576 gradini e, come avviene nei DVD audio, 24 bit corrispondono a ben 16.777.216 gradini), ma, benché gli audiofili più accaniti dissentano, per la grande maggioranza degli ascoltatori non dotati di orecchie da pipistrello un campionamento a 16 bit e 44,1 kHz è sufficiente per offrire una buona fedeltà del suono.
Negli usuali cd audio ogni "campione" è dunque un numero a 2 byte (o 16 bit, come preferite) che varia da -32.768 a +32.767.
Questo numero indica l'ampiezza dell'onda all'istante del campionamento. Così un'onda campionata che oscillasse indietro ed avanti da -32,768 a +32,767 sarebbe l’onda di volume massimo che questo formato potrebbe rappresentare, mentre un’onda oscillante tra -1 e +1 sarebbe quella a minor volume ed un gruppo di zeri in fila indicherebbe silenzio completo.
Questa serie di valori d’ampiezza è eccellente e permette di rappresentare accuratamente anche piccole variazioni di suono.
Tale campionamento audio digitale è noto con l’acronimo PCM che sta per Pulse Code Modulation.
Il PCM audio digitale produce un ritratto accurato del suono reale e solamente ascoltatori dotati di orecchio molto sensibile ed allenato e di buon equipaggiamento stereo possono distinguere tra esso e l'originale.
Il Compact Disc, con la tecnica della registrazione digitale, ha risolto tutti i problemi derivanti dalla registrazione analogica.
Quest'ultima, pur essendo efficiente, comporta sempre una perdita nella qualità del segnale, dovuta ai rumori e alle distorsioni prodotte su di esso dal supporto e dall'apparecchiatura di registrazione. Infatti ogni suono analogico è accompagnato da un rumore di fondo ed è limitato dalla larghezza di banda caratteristica degli strumenti impiegati per la registrazione. Le distorsioni sono vere e proprie perdite di informazioni, causate dalle imperfezioni costruttive dei circuiti elettrici in cui transitano i segnali e ai supporti di registrazione (vinile, nastro, ecc.), anch'essi incapaci di memorizzare una copia esatta del flusso sonoro originale.
Nei sistemi di registrazione digitale, invece, gran parte delle distorsioni viene eliminata grazie alla conversione del suono in un segnale digitale (cioè in una sequenza di valori binari, o bit), attraverso una tecnica detta di quantizzazione. Il passo successivo alla quantizzazione è la registrazione del segnale digitale come sequenza di bit On e Off, in base al già nominato schema di codifica del segnale chiamato PCM.
In questo modo i dati sonori memorizzati possono essere controllati, elaborati e restituiti con eccellente fedeltà. La notissima espressione "alta fedeltà" (Hi-Fi, dall'inglese High Fidelity) sottolinea proprio la corrispondenza quasi perfetta tra il suono registrato, trasmesso o riprodotto, e il suono originale. Gli eventuali effetti di distorsione provengono soltanto dal microfono, in ingresso, o dagli altoparlanti, in uscita.
Il meccanismo di riproduzione dei compact disc sfrutta i raggi laser e, poiché tra pickup ottico e supporto non vi è contatto, la qualità del suono non è soggetta a deterioramento.
Le tracce audio sono archiviate in formato numerico, riproducendo le stesse informazioni contenute del master creato nello studio di registrazione.
Volendo schematizzare i concetti sopra esposti, possiamo dire che, per ottenere un suono digitale fedele, bisogna essenzialmente considerare due variabili: la frequenza di campionamento e la profondità di bit.
| FREQUENZA DI CAMPIONAMENTO | PROFONDITA' DI BIT |
|
Numero di volte che un segnale audio in ingresso è misurato o "campionato" in un dato periodo di tempo. E' tipicamente indicata in kilohertz (kHz, migliaia di cicli per secondo). Per registrare in "CD-quality" audio è richiesta una frequenza di campionamento di 44.1kHz.
|
Accuratezza con quale è effettuata ciascuna misurazione o campione. Si riferisce alla lunghezza delle parole binarie (cioè sequenze di 0 e 1) usate per descrivere ciascun campione del segnale d'ingresso. Parole più lunghe permettono misurazioni più accurate e riproduzioni più fedeli di un segnale (maggior dinamica e minor distorsione). In un sistema a 16 bit, ciascun campione è rappresentato come una parola binaria lunga 16 cifre. Poiché ciascuna di queste 16 cifre può essere uno 0 o un 1, sono possibili 65.536 (216) valori per ciascun campione.
|
Il problema dello spazio occupato dai file sonori
È possibile ed abbastanza facile estrarre, "strappare" (in inglese, rip) i dati audio da un CD ed immagazzinarli in file di tipo WAV su un computer, per poi ascoltarli quando si vuole. Così, ipoteticamente, si potrebbero ascoltare ovunque copie dei brani musicali preferiti a questa alta qualità: sullo stereo di casa, su quello della macchina, sul lettore cd portatile, sul computer.
In realtà ciò non è fattibile a causa della grandezza dei file sonori.
Un piccolo calcolo matematico ci può far capire quanto spazio serve per immagazzinare informazioni sonore di questa qualità.
Abbiamo già detto che ogni campione è a 2 byte e che per ogni secondo ci sono 44.100 di questi campioni; inoltre bisogna ricordare che nella musica stereofonica ci sono 2 canali, uno destro ed uno sinistro.
Quindi per immagazzinare un secondo di musica stereo ci vogliono 176.400 byte (2 * 44100 * 2), che espressi in bit equivalgono a 1.411.200.
Dato che in un minuto ci sono 60 secondi, questo vuole dire che sono necessari 10.584.000 byte (176.400 * 60) e cioè circa 10 megabyte per immagazzinare un solo minuto di audio di qualità CD.
Ciò potrebbe anche non apparire troppo allarmante, dato che oggigiorno (2002) molti hanno hard disk di decine di Gigabyte ed alcuni addirittura di 120 o 180 Giga (senza parlare degli hd prossimi venturi, che prevedono capacità di 400 giga ed oltre). Tuttavia vi assicuro che si fa molto in fretta a saturare le capacità di qualunque hard disk, con programmi, musica, immagini e filmati.
Per non riempire fino all’orlo i nostri hard disk di file wav e per riuscire ad archiviare un numero maggiore di brani musicali su pc, e soprattutto su lettore portatile, si potrebbe ridurre la frequenza di campionamento: ad esempio, se tale frequenza è dimezzata (22.05 kHz invece di 44.01 kHz), viene considerata la metà delle misurazioni del segnale in ingresso, e così è prodotta solo la metà dei dati.
Ridurre a metà la frequenza di campionamento comporta una perdita di risoluzione, e quindi una minore fedeltà durante la riproduzione. E' esagerato dire che, passando da 44,1 a 22,05 kHz, la qualità del suono sarebbe ridotta a metà, ma sicuramente la registrazione sarebbe comunque in alcuni punti meno accurata per la metà. In particolare, la risposta in frequenza del sistema di registrazione sarebbe dimezzata. In effetti il dimezzamento della frequenza di campionamento comporterebbe che molte delle altre frequenze contenute nel suono originale sarebbero perdute e con esse molte armoniche, portando a registrazioni scarse per brillantezza e chiarezza.
Un altro modo per rendere più maneggevoli i file audio può essere quello di effettuare una registrazione monofonica (o di trasformare in mono una registrazione stereo), che dimezza ulteriormente la quantità di dati necessaria.
Tuttavia, la scelta di ridurre la dimensione dei file sonori tramite riduzione della frequenza di campionamento e/o il passaggio da stereo a mono non è generalmente accettabile perché si andrebbe incontro ad una notevole degradazione della qualità del suono.
Fortunatamente esiste una soluzione migliore: la cosiddetta compressione audio, cioè la tecnica di ridurre in maniera sensibile la dimensione dei file sonori pur mantenendo una qualità di ascolto vicina al suono originale.
In informatica esistono diversi metodi per compattare le informazioni in funzione di una maggiore efficienza nella loro trasmissione o memorizzazione. I metodi di compattamento sono usati in campi quali la trasmissione dati, la gestione di database, la trasmissione di fax e la realizzazione di CD-ROM.
Le diverse tecniche matematiche utilizzate per comprimere i dati possono essere classificate in base alla perdita di informazione che avviene nel processo di decompressione. In alcuni casi (testi, immagini radiografiche, file di dati o programmi) è necessaria un'accuratezza assoluta, garantita dagli algoritmi lossless di Huffman e di Lempen-Ziv Welch (LZW); in altri casi (suoni, immagini, filmati) la perdita di informazione è accettabile (ad esempio, algoritmi JPEG, MPEG).
In generale esistono
dunque due sistemi di compressione:
- Compressioni lossless (non distruttive, senza perdita di dati),
in cui i dati originali possono successivamente essere ripristinati
esattamente come erano. Esempi di compressioni lossless sono quelle utilizzate
nei noti programmi WinRar e WinZip.
- Compressioni lossy (distruttive, con perdita di dati),
caratterizzate dal fatto che, anche se i dati originali non possono essere
ripristinati esattamente come erano, i dati persi si considerano poco
significativi. Esempi sono la compressione JPEG per le immagini, la compressione
MPEG per i filmati e la compressione MP3 per l'audio.
Compressione "Lossless" (senza perdita di dati)
Con la compressione di tipo Lossless si generano dei file che sono più piccoli degli originali, ma che una volta decompressi ricreano file identici al 100% agli originali, senza che ci sia perdita di alcuna informazione.
Ad esempio, per comprimere un documento di testo o un programma si deve ricorrere alla compressione lossless, perché non ci si può permettere di perdere alcun dato (come potremmo leggere un documento o far partire un programma se mancassero delle parti?). A tale scopo sono molto utili programmi come WinZip o WinRar.
I file compressi con questa tecnica, tuttavia, non sono eseguibili: in altre parole, prima di lanciarli occorre sottoporli a decompressione, cioè ad un processo inverso a quello di partenza per decodificarlo, espandendoli alle dimensioni ed alle funzionalità originali.
Purtroppo comprimere i file audio in modo lossless non è affatto semplice. I citati programmi tipo Winzip riescono a comprimerli solo di poche unità percentuali.
Esistono compressori lossless particolari nati proprio per i file audio, ma anche questi arrivano in media a ridurre le dimensioni dei file di non più che il 50%. Ciò potrebbe essere anche sufficiente per qualcuno, ma di solito per rendere veramente portabili i nostri archivi musicali è necessaria una compressione maggiore.
Tra i compressori audio lossless ricordo innanzitutto quello considerato più completo e cioè Monkey's Audio, i cui file sono contraddistinti dall'estensione .ape (ape sta per "scimmia"), sviluppato da Matthew T. Ashland. Ha adottato di recente una licenza open source, distribuendo i codici sorgenti e offrendo lo sfruttamento senza restrizioni.
Tra gli altri lossless audio ricordo:
- Flac (Free Loseless Audio Codec), rilasciato sotto licenza Gpl e Lgpl (quindi gratuito e libero da brevetti), di cui sono disponibili e scaricabili front-end per Windows, Unix e MacOS X e che può essere compilato per le più diffuse varianti di Unix (Mac OS X, Linux, *BSD, Solaris), per BeOS, OS/2 e altre ancora.
- Lpac, creato da Tilman Liebchen, che, a fronte di una compressione senza perdita del segnale, garantisce un risparmio minore di circa il 50% rispetto a Mp3. I file Lpac recano l'estensione .pac e la tecnologia è disponibile oltre che per Windows (esiste un plug-in per il popolare player Winamp) anche per Linux e Solaris.
-
Shorten, sviluppato da Tony Robinson della Softsound, che crea dei file con
estensione .shn, compressi e lossless ma dalla notevole pesantezza,
all'incirca il 50% dell'originale. Eventualmente è possibile optare per una
compressione "lossy", che "rovina" il segnale ma genera file più piccoli. La
peculiarità di Shorten è che per ogni file, in fase di creazione, vengono
prodotti altri file collegati che ne descrivono caratteristiche e informazioni
supplementari o che ne attestano la genuinità. Programmi per ascoltare, creare o
anche solo convertire i file Shorten esistono per tutte le versioni di Windows,
Macintosh e Linux/Unix.
Compressione "Lossy" (con perdita di dati)
Una metodica di compressione viene definita "lossy" quando causa una perdita di informazioni.
Decomprimendo un archivio precedentemente compresso in modalità lossy si ottiene qualcosa di più o meno simile all'archivio originale, ma non identico.
Questo tipo di compressione con perdita di dati può anche essere catastrofico per programmi che devono essere interpretati da un computer, ma spesso può andare più che bene per le esigenze uditive degli esseri umani: il trucco consiste nel rimuovere piccole parti di informazioni in luoghi dove ciò non può essere percepito.
La compressione audio lossy si basa sui principi della cosiddetta psicoacustica, scienza che studia il modo in cui i suoni vengono percepiti dagli esseri umani, cioè che studia il suono in relazione alle sensazioni uditive, sotto il profilo fisiologico e psichico, e in particolare l’intensità della sensazione sonora in relazione al potere localizzatore uditivo dell’orecchio umano.
I metodi impiegati per ridurre le dimensioni dei file audio si basano su studi recenti, che hanno permesso di capire che l'udito umano di solito non è in grado di percepire tutti i suoni provenienti da un impianto stereo Hi-Fi.
Infatti, la maggior parte delle persone (e in modo particolare quelle non più giovani) è solitamente incapace di udire le frequenze superiori ai 15 kHz, soprattutto se tali suoni acuti sono mischiati con suoni di tonalità inferiore, cosa che accade normalmente nei brani musicali. Per questo, è possibile evitare di memorizzare quasi un quarto delle informazioni contenute in un segnale audio digitale (che considera un intervallo di frequenze da 15 Hz a 20 kHz).
Inoltre, i rumori improvvisi e forti (come ad esempio i colpi di tamburo) fanno vibrare intensamente il timpano delle nostre orecchie, il quale diventa così incapace di reagire ai suoni più deboli immediatamente successivi, distanti pochi millisecondi. A causa di questo fenomeno, chiamato mascheramento acustico, le note che seguono i picchi acustici possono essere eliminate senza che l'ascoltatore si accorga di alcuna perdita di informazioni.
Si è anche appurato che l'udito umano non riesce a percepire i suoni di intensità inferiore a quella del rumore di fondo e, soprattutto, che la soglia del rumore percepibile varia a seconda dei suoni emessi: più alto è il volume di ascolto e più alta risulta la soglia del rumore (per esempio, è esperienza comune il fatto che non si riesca a sentire le parole dette da una persona a noi vicina mentre ci si trova in una discoteca o in una strada con traffico intenso). Per tali motivi, in fase di compressione si possono eliminare i suoni che si trovano sotto la soglia del rumore, senza apparente degrado.
Il lavoro più difficile dei ricercatori è consistito nello sviluppo di modelli psicoacustici affidabili, capaci di descrivere con precisione l'andamento del livello di rumore udibile, in funzione sia della frequenza sia dell'entità della pressione sonora. Si è visto che questa soglia ha valori piuttosto alti per le note gravi ed acute, mentre è a livelli più contenuti per i suoni tra i 2,5 e i 5 kHz (dove la sensibilità dell'orecchio umano è molto buona).
Per ridurre ulteriormente il flusso di dati, in fase di compressione lossy si possono codificare come monofonici i segnali stereo che risultano identici su entrambi i canali. Questa operazione, però, si effettua di solito solo quando si selezionano i bit rate più bassi, visto che danneggia comunque anche le informazioni che sono diverse nei due canali destro e sinistro.
Grazie al notevole successo degli studi sulla psicoacustica, ogni gruppo di ricercatori ha sviluppato i propri algoritmi di compressione lossy, che producono file codificati in formati diversi, tra loro incompatibili e in genere protetti da brevetti a livello mondiale.
Attualmente i tipi di archivi più famosi sono Mp3, MP3 Pro, Real Audio, Wma, Ogg Vorbis, Mpc e AAC.
Mp3
E' probabilmente il formato più conosciuto ed è da tempo diventato quasi sinonimo di musica compressa.
Gli studi che hanno portato allo sviluppo di questo formato lossy sono iniziati nel 1987 con l'analisi delle possibili codifiche audio di tipo percettivo. Queste ricerche sono state effettuate presso l'istituto tedesco Fraunhofer IIS-A di Monaco, in collaborazione con l'Università di Erlangen, e hanno portato alla standardizzazione del formato Iso Mpeg Audio Layer-3 (IS 11172-3 e IS 13818-3), conosciuto con la sigla Mp3.
Il software sviluppato esegue una compressione che avviene nel dominio delle frequenze, individuando ed eliminando i suoni superflui grazie all'impiego di una modellazione del rumore su base percettiva.
Lo spettro sonoro è suddiviso in 576 intervalli, ciascuno trattato separatamente.
La risoluzione di campionamento è ridotta da 16 bit ad un valore variabile tra 2 e 15 bit, a seconda delle frequenze prese in esame.
Infine, il codice sfrutta anche l'algoritmo di Huffman (algoritmo compressivo lossless, cioè non distruttivo, ideato nel 1952 dal matematico D.A. Huffman) per evidenziare e per scartare i bit ridondanti nel flusso dei dati sonori. Questa è una operazione di compressione su dati, non sul suono. Il lavoro svolto da questo algoritmo serve soprattutto ad ordinare correttamente i dati che compongono i file, e si attiva in chiusura della compressione MP3. Il lavoro svolto da questo algoritmo è quello di ordinare e codificare le ricorrenze consecutive dei simboli nel. Naturalmente, più ci sono ricorrenze consecutive e più i dati saranno compressi. Questa tecnica di compressione è il complemento perfetto per la codifica percettiva MP3, soprattutto perché se un brano è ripetitivo ci saranno moltissimi dati perfettamente codificati per l'orecchio umano, ma eccessivi, inutili o ridondanti, perché la musica è ripetitiva. Ed è in questo contesto che la codifica Huffmann ha le maggiori possibilità i "comprimere i dati".
Il processo finale è tale da fornire, con un flusso di dati di 128 kbit per secondo, una qualità sonora simile a quella di un CD audio, che invece richiede un flusso di 1.411,2 kbit al secondo. Si ottiene così una riduzione della dimensione dei brani di circa 10-12 volte.
Una caratteristica dei file mp3 è la memorizzazione, insieme ai dati audio, di informazioni accessorie, come il nome dell'autore, il titolo del brano, l'album di origine e l'anno di pubblicazione. Questi dati sono raccolti in gruppi di byte chiamati tag Id3, che sono lunghi fino ad un massimo di 28 caratteri ciascuno.
I tag sono poi a loro volta raccolti in due insiemi, chiamati Id3v1 e Id3v2: il primo gruppo è incluso anche nei formati Ogg Vorbis e Wma, mentre il secondo è una peculiarità dei soli file mp3 e può contenere note, testo della canzone e diversi Url.
Per una trattazione più approfondita della codifica Mp3 clicca qui <<<<<<<
Mp3 Pro:
il finto successore di Mp3
Il formato di compressione lossy Mp3 Pro (sviluppato dalla società svedese Coding Technologies e annunciato nel 2001 da una sua partner, la società francese Thomson) "dovrebbe" rappresentare l'evoluzione del più celebre formato Mp3.
Il nuovo algoritmo, secondo le dichiarazioni della Thomson,
sarebbe" in grado di offrire la stessa qualità d'ascolto dell'Mp3, ma con un bitrate dimezzato: ad esempio, un Mp3 Pro a 64 kbps sarebbe qualitativamente pari ad un Mp3 tradizionale a 128 kbps.
L'encoder Mp3 Pro impiega la nuova tecnologia SBR (Spectral Band Replication), che divide i suoni in due blocchi: il primo blocco contiene le basse frequenze ed è codificata in un normale flusso Mp3; il secondo blocco contiene le frequenze alte, che sono trattate e compresse in una parte del flusso Mp3 di solito ignorata dai codec tradizionali.
La suddivisione dell'audio in due parti permette di far lavorare in maniera ottimale l'algoritmo di codifica, con l'ulteriore vantaggio di garantire la compatibilità verso il basso con i lettori di Mp3 meno recenti.
In fase di ascolto, il nuovo codec legge entrambi i gruppi di dati e li unisce in un solo flusso, in modo da fornire una risposta in frequenza più ampia rispetto ai sistemi che impiegano il vecchio sistema di codifica.
Per altre notizie visita il sito mp3pro zone
AAC:
il vero successore dell'Mp3
Nel
corso di molti anni il
Fraunhofer Institute for Integrated Circuits IIS-A ha portato contributi
notevoli al successo della standardizzazione della codifica audio. La
cooperazione internazionale di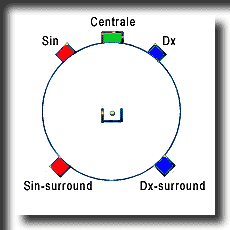 Fraunhofer con società come AT&T, Nokia, Sony e Dolby ha determinato la nascita
di un efficiente metodo MPEG di compressione audio chiamato MPEG-2 Advanced
Audio Coding (AAC) e dichiarato standard internazionale da MPEG già nel
lontano aprile 1997.
Fraunhofer con società come AT&T, Nokia, Sony e Dolby ha determinato la nascita
di un efficiente metodo MPEG di compressione audio chiamato MPEG-2 Advanced
Audio Coding (AAC) e dichiarato standard internazionale da MPEG già nel
lontano aprile 1997.
Il fatto che AAC sia pressocché sconosciuto alla massa, nonostante sia presente sulla scena da anni, è probabilmente legato all'enorme successo avuto dallo standard Mp3 nella distribuzione di musica attraverso Internet.
A guidare lo sviluppo di AAC è stata la ricerca di un metodo di codificazione efficiente per i segnali surround, come ad esempio quelli a 5 canali (sinistro, destro, centrale, sinistro-surround, destro-surround) usati nei cinema.
Per un po' di tempo sci sono stati algoritmi per questi segnali in MPEG-2. Comunque, non fu raggiunta una efficienza ottimale per ragioni tecniche e storiche.
Così, lo scopo principale di questo tipo di codifica rimase quello di ottenere una riduzione considerevole del bitrate necessario e, nello stesso tempo, di migliorare la qualità di riproduzione sonora.
MPEG-2 AAC è la conseguente continuazione del metodo di codifica audio MPEG-1 Layer III (Mp3) sviluppato all'università di Erlangen. L'estesa cooperazione con partner internazionali e le conoscenze derivate dallo sviluppo del formato Mp3 hanno costituito la base di sviluppo per questo metodo di codificazione che è attualmente tra i migliori in assoluto.
Con frequenze di campionamento comprese tra 8 kHz e 96 kHz, un numero di canali tra 1 e 48, 15 canali di miglioramento a bassa frequenza e capacità multilingua, il metodo AAC è già pronto per sviluppi futuri nel settore audio. Per la compressione usa tecnologie molto avanzate tra cui l'algoritmo di Huffman , quantizzazione e misurazione di scala, matrici M/S, intensità stereo, accoppiamento dei canali, previsione a ritroso, TNS (Temporal noise shaping), Trasformata Coseno Discreta Modificata (IMDCT), controllo del guadagno e filtraggio ibrido.
A parità di bitrate, un file in formato AAC ha una qualità del 30% superiore a quella di un file in formato Mp3. In altre parole, per fare un esempio, un AAC a 128 kbps ha la stessa qualità di un mp3 a 192 kbps.
AAC può archiviare dati compressi di 5 canali a banda piena con un output indistinguibile dall'originale con un bitrate di 320kbps (quindi, 64 kbps per canale), mentre l'MP3 potrebbe raggiungere analoghi risultati soltanto intorno agli 890 kbps.
Inoltre, alcuni sample quasi impossibili da codificare con MP3 hanno una qualità sonora molto buona anche a medi bitrate con AAC.
La nuova tecnologia SBR (Spectral Band Replication), che divide i suoni in due blocchi (uno perle basse frequenze ed uno per le frequenze alte) può essere aggiunta a qualsiasi codifica compressiva audio oggi in uso.
Così come Mp3Pro è SBR aggiunta agli MP3, così AAC+ (da leggersi "AAC Plus") è SBR aggiunta ad AAC. Questo AAC potenziato da SBR può rappresentare con buona qualità un brano stereo a 44.1 khz anche a bitrate di soli 32 kbps, ben quattro volte di meno rispetto ai soliti mp3 a 128 kbps.
Real Audio
Lo sviluppo di questo formato di compressione audio è iniziato nel 1995, quando la società Real Networks ancora si chiamava Progressive Networks.
L'algoritmo di compressione nacque con l'obiettivo iniziale di permettere lo streaming attraverso il Web, per consentire agli utenti di ascoltare i suoni anche mentre è in corso il download dei dati, in modo da ridurre al minimo i tempi di attesa.
Il software originale era tarato principalmente per la voce umana, ma in seguito è stato modificato per coprire un più ampio spettro di frequenze.
I calcoli necessari per la codifica e per la decodifica sono piuttosto complessi e quindi bisogna disporre di processori potenti (caratteristica che oggi è ampiamente soddisfatta, ma che ai tempi dell'introduzione di questo formato ha creato problemi agli utenti).
Nei file di tipo Real Audio sono incluse anche le informazioni per la gestione dei diritti d'autore, ma non è consentito l'aggancio dei dati accessori Id3, come il nome dell'autore e il genere musicale.
Wma
Il codec Wma (Windows Media Audio) rappresenta il formato di compressione per i segnali audio sviluppato dalla Microsoft Corporation (in parallelo con Wmv, dedicato al video di tipo streaming).
Anche il codec Wma si basa su sistemi di compressione che applicano un modello psicoacustico per individuare le frequenze che possono essere eliminate senza che l'ascoltatore percepisca un netto degrado della musica.
I file musicale in formato Wma integrano sia le informazioni relative al copyright (rintracciabili tra i dati audio grazie alla tecnologia DRM, Digital Rights Management), sia i tag Id3 in versione Id3v1 (che, ormai sappiamo, consentono la memorizzazione di informazioni accessorie relative al brano musicale compresso).
Ogg Vorbis
L'ideatore di questo formato di compressione audio lossy è Christopher Montgomery, americano di 29 anni, diplomato in informatica al Massachusetts Institute of Technology, impiegato presso la società Fast Engines, dove sviluppa software.
Nel settembre 1998 prese la decisione di creare un nuovo formato di audio compresso che fosse libero da brevetti e uguale o superiore a quello Mp3, in quanto venne a sapere che l'istituto tedesco Fraunhofer minacciava di portare davanti ai giudici la maggior parte dei creatori di encoder MP3. Infatti, contrariamente a quello che molti credono, l'MP3 non è affatto gratuito: ogni volta che un utente della Rete scarica un software per leggere file MP3, l'editore versa circa 80 centesimi di euro a Thomson Multimedia (che gestisce i diritti del Fraunhofer); anche i siti che propongono degli archivi MP3 scaricabili devono versare, sempre a Thomson Multimedia, il 2% del loro introito annuale.
Per dare un nome al suo progetto Christopher si è ispirato al personaggio di un bandito chiamato Vorbis, protagonista di un racconto dello scrittore di fantascienza Terry Pratchett, e a Ogg, una tattica del videogioco online Netrek. E' nato così il software Ogg Vorbis e, di conseguenza, i file hanno come estensione ".ogg".
Gli algoritmi sviluppati per il formato Ogg Vorbis si basano su principi di psicoacustica simili a quelli impiegati per l'Mp3, con l'importante differenza che quelli Ogg Vorbis non sono protetti da alcun brevetto: infatti, il codice, ideato inizialmente da Montgomery e, successivamente, ampliato dal gruppo di sviluppatori noti come Xiphophorus, (dal nome di una famiglia di pesci dell'America centrale utilizzati nella ricerca contro il cancro) è open source, cioè aperto a chiunque voglia contribuire alla sua evoluzione, seguendo un processo di crescita che ha molti punti in comune con la strada percorsa dal sistema operativo Linux. La maggior parte degli altri formati di compressione, come abbiamo già visto per gli mp3, è invece brevettata pesantemente ed ermeticamente controllata.
Questo significa che i produttori di hardware che vogliono supportare Ogg Vorbis nei loro lettori musicali portatili, possono farlo senza pagare alcuna royalty (tassa di licenza), diversamente da quanto accade con altri formati di compressione. Anche gli sviluppatori di software possono usare gli Ogg Vorbis nei loro giochi senza dovere prima ottenere il permesso dalla società potente e senza pagare royalties.
In realtà il nome "Ogg" indica una famiglia di compressori, ciascuno dedicato ad un tipo particolare di flusso di dati multimediali, in cui Ogg Vorbis rappresenta il compressore audio lossy, Ogg Flac il compressore audio lossless, Ogg Tatkin il compressore video.
Anche il formato Vorbis di Ogg, come l'Mp3, impiega un flusso di dati che può essere costante o variabile (CBR e VBR, vedi oltre). E' però interessante notare che, mentre l'Mp3 pone l'accento sui bitrate, l'Ogg Vorbis offre come unica regolazione un parametro che determina la qualità dei suoni compressi.
Per esempio, un file codificato in formato Ogg Vorbis a qualità 3 dà luogo ad un bitrate medio di 112 kbps, ma sembra migliore di un mp3 a 128 kbps (oltre che essere più piccolo) e spesso di qualità pari a quella di un mp3 codificato a 160 kbps.
Con un Ogg Vorbis a qualità 2 si ottiene un file di qualità quasi uguale a quella di un mp3 a 128 kb, ma più piccolo del 25%.
In pratica, con gli Ogg Vorbis si può avere la stessa qualità degli mp3, a bitrate medi, risparmiando spazio, oppure si può occupare lo stesso spazio degli mp3, ma con qualità migliore. C'è però da dire che agli alti bitrate gli mp3 creati con Lame e preset di Dibrom sono di qualità sempre migliore degli ogg.
I codificatori Ogg Vorbis non considerano più di tanto i bit-rate (e comunque di default usano la modalità VBR), mentre usano invece una quality-rate che varia da -1 a 10 (anche se nessuno è in grado di percepire le differenze una volta superata la qualità 7), con incrementi di 0.01 .
Le altre caratteristiche di Ogg Vorbis sono il supporto di un massimo di 256 canali audio discreti (e non i semplici due canali destro e sinistro), che gli permette quindi di essere usato per i sistemi surround di nuova generazione, la possibilità di inserire estesi commenti testuali, molto più estesi che nei tag Id3 dell’Mp3, e la capacità di ridurre ulteriormente il bitrate di un file già compresso senza che ci sia perdita di qualità (perdita che, invece, è di solito associata alle tradizionali operazioni di una decompressione e di una successiva compressione più spinta).
Per notizie più dettagliate visitate il sito (in inglese) www.vorbis.com
Mpc (Musepack)
Mpc è un formato di compressione audio che, per ibitrate superiori a 160 kbps, permette di ottenere file di qualità sonora decisamente superiore a quella degli mp3 e di qualsiasi altro file audio lossy.
Per maggiori informazioni potete visitare questi siti:
Andree Buschmann home page, sito ufficiale del creatore del formato mpc;
Musepack.org, ricco di informazioni aggiornate, dal quale si possono scaricare encoder e decoder;
il forum hydrogenaudio.org;
Due parole sui Bit Rate (o Data Rate)
La grandezza dei file audio compressi in modo lossless è, in ultima analisi, determinata dal cosiddetto bitrate (o datarate), cioè la quantità di bit (dati) usati dal programma compressore (ad esempio, un encoder) per rappresentare ogni secondo di audio (più in generale, il bitrate rappresenta la quantità di bit che transitano in un dispositivo nell'unità di tempo, di solito pari ad un secondo).
Abbiamo prima ricordato che per immagazzinare un secondo di musica stereo in un normale CD audio ci vogliono 176.400 byte, che equivalgono a 1.411.200 bit, cioè a poco più di 1.411 kilobit per secondo (kbps).
I formati di compressione lossy tipici usano solamente un range che va da 64 a 320 kbps per immagazzinare le stesse informazioni.
Il problema è che il bitrate di un brano si riferisce più che altro alla grandezza del file e non alla sua qualità.
Per esempio, si potrebbe scrivere una formato di compressione che realizza un bitrate di 256 kbps prendendo solamente i primi 256.000 bit dei ciascun gruppo di 1.411.200 bit in un determinato secondo. Anche se probabilmente alcune persone potrebbero presumere che una canzone codificata in questo modo dovrebbe essere migliore del tipico 128 kbps degli mp3, sarebbe sufficiente ascoltare i brani codificati nelle due modalità suddette per notare subito che il tipico 128 è assolutamente migliore di un eventuale 256 creato nel modo suddetto.
Il fatto è che i file mp3 rappresentano il primo esempio di compressione audio lossy comparso sulla scena ed essendo diventato rapidamente ed estesamente famoso in tutto il mondo ormai moltissime persone associano il concetto di bitrate a quello di qualità.
In altre parole, ormai in molti credono che più è alto il bitrate e più è alta la qualità del brano compresso.
In realtà, anche all'interno della classe degli mp3, ed anche all'interno di un solo bitrate (ad esempio, 128 kbps), la qualità del suono ottenuta con diversi codificatori varia drasticamente.
Per esempio, l'encoder Xing è veloce, ma produce mp3 scadenti, anche a 128 kbps. Il codificatore Lame, invece, è un po' più lento, ma produce file sonori di gran lunga migliori, anche allo stesso bitrate.
Codificatori lossy più recenti, come ad esempio gli Mpc, usano differenti modelli psicoacustici e, a determinati bitrate, generano file sonori di qualità nettamente migliore rispetto anche al miglior encoder mp3.
Vogliamo confonderci ancor più le idee? ;-))
ABR? VBR? CBR?
Se vogliamo ancor di più confonderci le idee, diciamo che non basta parlare "semplicemente" di bitrate.
I primi codificatori di mp3 (e la maggior parte anche oggi) usavano il cosiddetto ABR (Average Bit Rate, cioè il bitrate medio).
Se, per esempio, noi codifichiamo un file a 128 kbps in ABR, il codificatore userà in media 128 kbit per codificare ciascun secondo della canzone, senza distinzioni.
Quindi la prima misura (che magari consiste di solo due colpi di tamburo) userà 128 kilobits e rappresenterà quasi precisamente quel secondo.
Però, in un altra parte della canzone, dove magari il chitarrista sta andando in estasi in un assolo da paura con la sua Gibson Les Paul, il batterista si sta contorcendo in piroette su tamburi e piatti e il bassista sta suonando un sottofondo martellante, il codificatore dovrà ancora usare un valore vicino a 128 kilobits per codificare quel secondo, dove avrebbe potuto invece usare, ad esempio, 320 kbit. Quel secondo di assoli sarà quindi rappresentato piuttosto poveramente.
Encoder mp3 più recenti (come ad esempio l'ottimo Lame) supportano il cosiddetto bitrate variabile (VBR, Variable Bit Rate). Questo dà al codificatore la libertà di "risparmiare" bit in alcuni secondi di musica semplice e di usare un numero maggiore di bit per rappresentare quei secondi in cui la musica è più complessa.
In questo modo si ottengono file di solito di grandezza uguale o lievemente più piccola rispetto a quella dei file codificati in ABR allo stesso bitrate. Nello stesso tempo, però, queti file in VBR hanno una qualità sonora complessivamente migliore dei rispettivi ABR.
Esistono poi anche gli mp3 detti "a bitrate costante" (CBR, Constant Bit Rate).
In questi file l'encoder dovrebbe usare esattamente lo stesso ammontare di bit per ogni secondo di musica, con uno spreco notevole di bit e, quindi, di spazio occupato dal file mp3.
In realtà, anche negli mp3 etichettati come CBR di solito si usano delle medie di bitrate calcolate su piccoli periodi di tempo, e quindi tecnicamente non si dovrebbe parlare di bitrate costante (CBR), bensì sempre di bitrate medio (ABR). È improbabile che alcun formato audio compresso usi un CBR puro.
Purtroppo, sebbene alcuni tra i più recenti encoder supportino il VBR, molti lettori portatili non riconoscono gli mp3 creati in questo modo.
Ma anche quando i loro codificatori e i loro player supportano il VBR, molte persone non lo usano per chissà quale ragione (abitudine? Ignoranza?)
La maggior parte dei più nuovi codificatori lossy supporta il VBR, sebbene spesso non sia settato come default.
Non guardate semplicemente i numeri,
USATE LE ORECCHIE!
Basate le vostre scelte NON sui BITRATE,
BENSI' sulla QUALITA' del suono
Alcuni test effettuati da Fraunhofer e Thomson dimostrarono che, per gli mp3, 256 kbps era la vera "qualità-CD"; in altre parole, i loro ingegneri del suono riuscirono solo raramente a distinguere la differenza tra i CD originali e tali mp3. Questi file erano grosso modo di grandezza pari al 20% di quella del file audio originale, ma virtualmente erano indistinguibili per qualità.
Da allora in poi, gli mp3 a 128 kbps sono diventati lo "standard", perché anche se la maggior parte delle persone con buona attrezzatura audio può avvertire nettamente la differenza rispetto all'originale, tali file sembrano ancora sufficientemente buoni per l'ascoltatore medio.
Un altro motivo per cui gli mp3 a 128 kb si sono imposti come standard è che essi sono relativamente piccoli, cioè di grandezza pari a solo circa il 10% rispetto a quella del brano originale, cosa che li rende di facile immagazzinamento nei pc e nei lettori portatili e di facile scambio attraverso Internet.
Certamente esistono anche persone (con ignoranza e/o con orecchi ottusi e/o con cattiva attrezzatura e/o con l'irrazionale desiderio di immagazzinare il massimo numero di file possibile) che codificano brani mp3 a 64 kbps. Questi file sono effettivamente molto piccoli, dato che hanno dimensioni pari al 5% rispetto agli originali, ma hanno una qualità sonora decisamente scadente, più o meno come quella dei brani trasmessi dalla radio in FM.
Il problema è che queste regole valgono solamente per gli mp3.
Come abbiamo già accennato, però, oggi esistono formati di compressione decisamente migliori rispetto agli mp3, sviluppati su modelli psicoacustici più raffinati.
Possiamo, per concludere, stilare una classifica dei migliori compressori audio lossy?
Probabilmente nel momento in cui scrivo (giugno 2003) si può dire che ai primi posti di questa ipotetica classifica qualitativa ci sono:
1° - MPC (Musepack)
2° - AAC
3° - MP3 encodato con Lame (versione 3.90.3, e NON superiori, e usando i preset di Dibrom)
4° - Ogg Vorbis
______________________________________
I dati che avete trovato in questa pagina sono desunti da conoscenze personali, traduzioni, lettura di articoli di riviste informatiche varie, consultazione di enciclopedie cartacee e digitali e da lettura di pagine web e post sui newsgroup .
![]()